
Dropbox Backup Information Architecture
Client Problem Statement
Dropbox Backup is Dropbox’s product that automatically backs up important files on your devices, like your computer and external drive, and easily restore them. The team is interested to understand how intuitive information architecture may create a better user experience.
This project was assigned through my Summer 2022 internship with Dropbox.
Objectives + Goals
Project Objectives
Understand user cases and workflows for Backup actions
Identify pain points and areas of improvement for IA of current Backup product
Provide direction on information architecture, UI and content design for Backup actions
Research Questions
What is the current user’s depth of understanding around how to perform Backup’s core actions?
What approach to information architecture should we have for Backup that reflects user mental models?
How might structural changes to the Backup actions page information architecture result in improved product engagement and user experience?
How do users’ mental models around Backup actions, concepts, and content influence how they work with the product?
What strategy to content design and naming should we take for Backup?
Methodology
x2 rounds of research were conducted to understand user mental models regarding Backup-related actions, and the relative importance of specific actions when considering a backup or file recovery solution.
Secondarily, observational data was collected to understand user navigational patterns on the existing interface across web and desktop surfaces. These qualitative observations were compared and contrasted to product user data.
Participants were sourced globally to reflect Dropbox Backup’s existing user base. Care was taken to maintain an even spread across Dropbox’s Customer Characters (similar to personas).
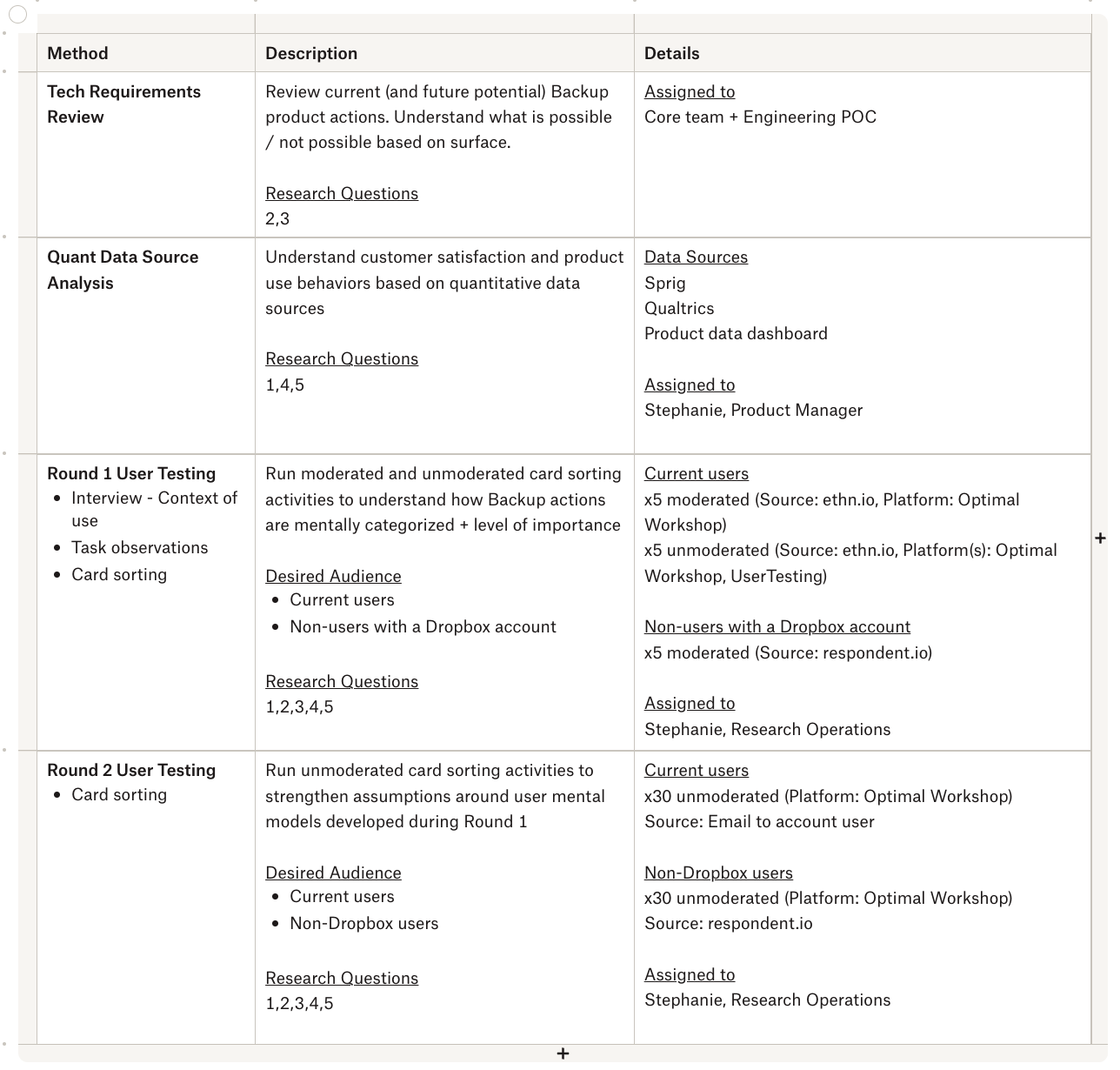
My Role
I designed, kicked off, and conducted the study full-cycle.
I worked with a core team including representation from Product Design, Product Management, and Content Design and collaborated during study design, user interviews, and synthesis. I was also supported by a UX Research mentor and other Design and Research peers who provided feedback throughout the experience.
Research
Research plan
A 7-week timeline was socialized at project kickoff. Due to intern program time constraints, there was a specific focus on roles and responsibilities and how important dates (PTO or OOO dates, etc) that may impact the core team’s bandwidth.
Study activities were categorized into two buckets:
Independent activities by Design Research
Activities requiring collaboration with the core team.
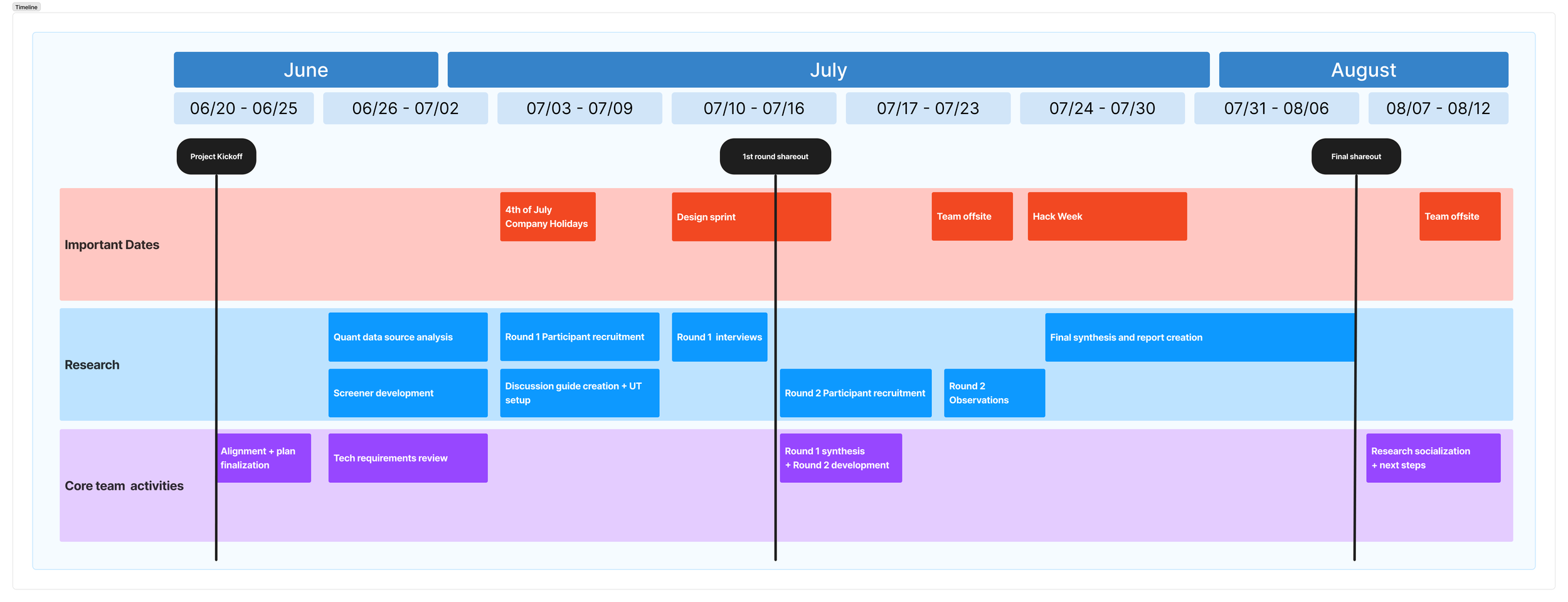
Project timeline and key activities
Research toolkit
The moderated and unmoderated studies were implemented using an array of SaaS products available to the Research team.

Participant recruitment tools

Card sorting and unmoderated observation tools
Synthesis
Findings from both rounds of user studies were synthesized using a combination of spreadsheets (usability tracking, qualitative coding, product data analysis) and visual whiteboards (Miro).
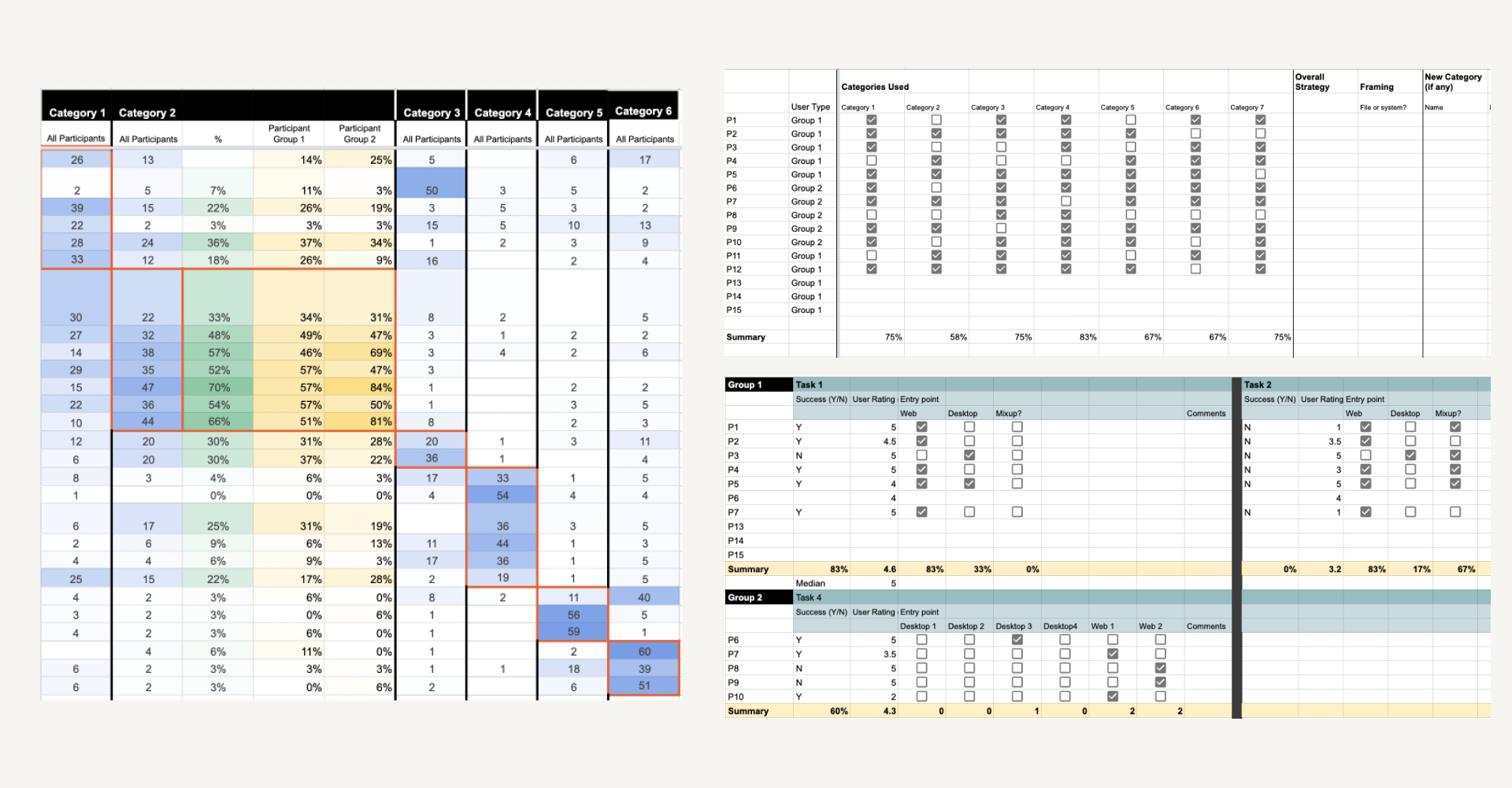
Left, top right: Examples of spreadsheets used during card sorting synthesis
Bottom right: Annotation spreadsheet used during task observations

Left: Affinity diagram of qualitative feedback from Round 1 and 2 observations
Right: An example of a visual heat map to illustrate most common user interactions across screens and surfaces
Deliverables
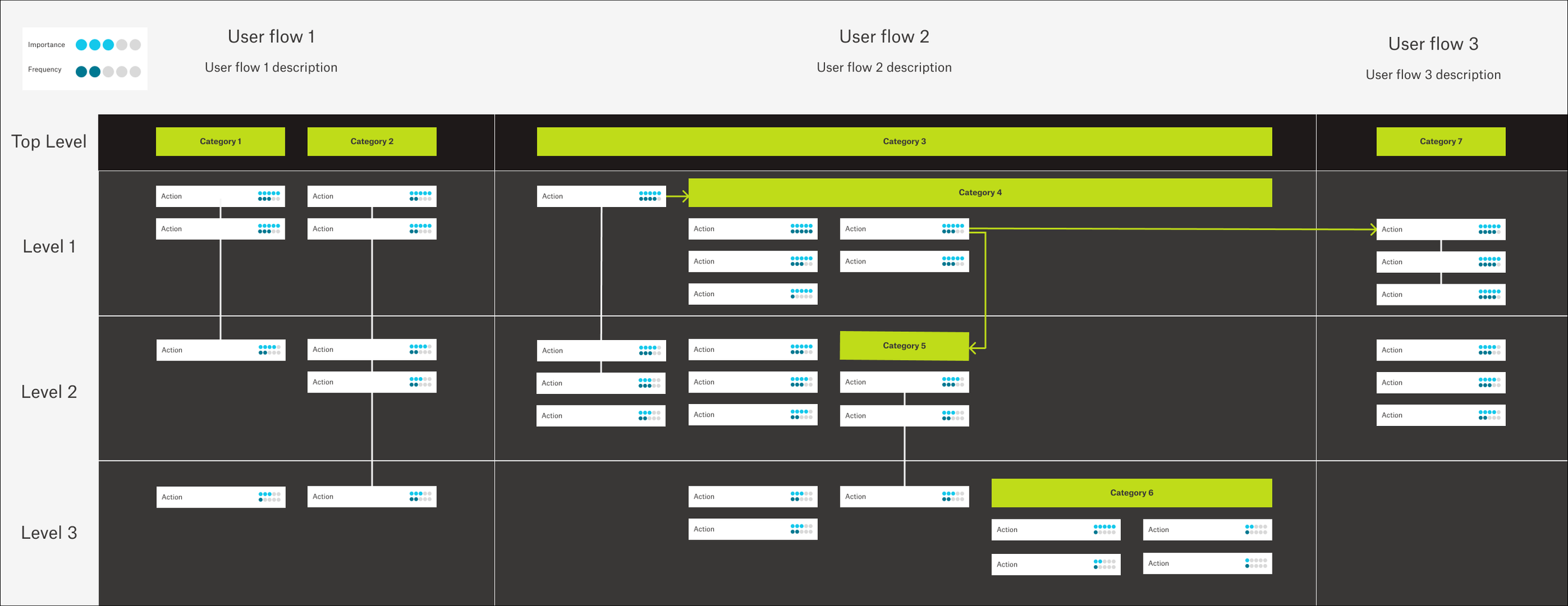
Information Architecture Map outlining key user flows and actions by mental hierarchy
Along with a final research report including full findings and recommendations, a series of artifacts were generated for team guidance during the product development process.
These artifacts are meant to be living documents and have been transferred to functional team members for future maintenance.
Information Architecture Map (see above visual): A blueprint outlining key user flows, how key Backup actions relate to one another, where they sit in user mental hierarchy. The map may be modified as new Backup actions or user insights are generated.
Information Architecture Guidelines: A set of rules that illustrate Backup user mental models and examples of how they are applied. These guidelines may be used during future IA modification.
Language Library: A list of approved terms that display positive resonance to users, with definitions and synonyms. This library may be leveraged by Content Design and Product Marketing.
Guidance by Surface: Specific product recommendations based on user preference across Web and Desktop surfaces.
Reflection
Research impact
Socialization
Through synchronous (realtime meetings) and asynchronous (Slack, wiki) channels, the study’s findings were socialized with the Backup team and across Engineering, Product, and Design. Apart from the Backup team, the research findings also proved relevant to the Core Experience and Desktop Experience teams. Combined, these teams own the product experience for Dropbox’s flagship File, Sync, and Share product as well as embedded Mac and PC experiences.
Backup Design
The team is considering an alternative UI based on the recommended information architecture. During research wrap up, I partnered with Product Design on a series of rapid prototypes and research-based critiques.
Marketing / Pricing Strategy
Some of the findings have led to product marketing considerations, such as what language to use when describing the product’s value proposition. This research was also cited during a Backup product Q&A, specifically around pricing strategy.
What I would have done differently
Unmoderated study - chunking activities across more participants
During Round 1 user studies, the unmoderated study was built in User Testing in a duplicate format to the moderated interview script. This included activities across three platforms over 30 minutes:
Behavioral open-ended questions
Usability testing (3 tasks)
x2 rounds of card sorting
Due to complicated instructions and an underperforming incentive value, completion rates were unsuccessful and the desired n-count for unmoderated participants was not met.
In retrospect, I would modify the original unmoderated study design into two separate tracks and sourced across a wider sample population:
Unmoderated Group 1: Usability testing only (3 tasks)
Unmoderated Group 2: Card sorting only (2 scenarios)
I believe this would lead to more user engagement and higher completion rates.
More time flexibility
Conducting the study within the confines of a 12-week internship resulted in time pressure unrealistic to a real-world setting. For instance, research share out dates were scheduled not based on the best availability for all relevant stakeholders, but rather based on dates that would work before my last day at Dropbox. When also considering summer vacation calendars, about 50% of study activities were implemented with at least one key stakeholder absent.
In an ideal world, I would want:
Twice as much time to synthesize findings and write the report (actual: 1.5 weeks)
Subsequent rounds of iteration to ensure the final artifacts were useful tools. For instance, I was able to solicit feedback from Product Design as the Information Architecture Map was built, but was unable to do the same with Content Design for the Language Library.
The opportunity to represent my findings at a wider range of synchronous channels, such as design critiques and other team meetings.
One of the most valuable lessons I learned during this internship was the idea of research as a team sport, and that perfection should not restrict research from being socialized to select collaborators. Rather, bringing stakeholders along the entire research process in a stronger end result, which requires sensitivity to stakeholders’ availability across other priorities.
Quantitative validation
Time permitting, I would love to validate specific research recommendations (especially those under the Information Architecture Guidelines) by partnering with Data Science to translate these hypotheses into quantifiable measurements.